
TO BE UPDATED SOON
DeepPose for canonical 3D pose estimation of (medical) images
A general Riemannian formulation of the pose estimation problem to train CNNs directly on SE(3) equipped with a left-invariant Riemannian metric.
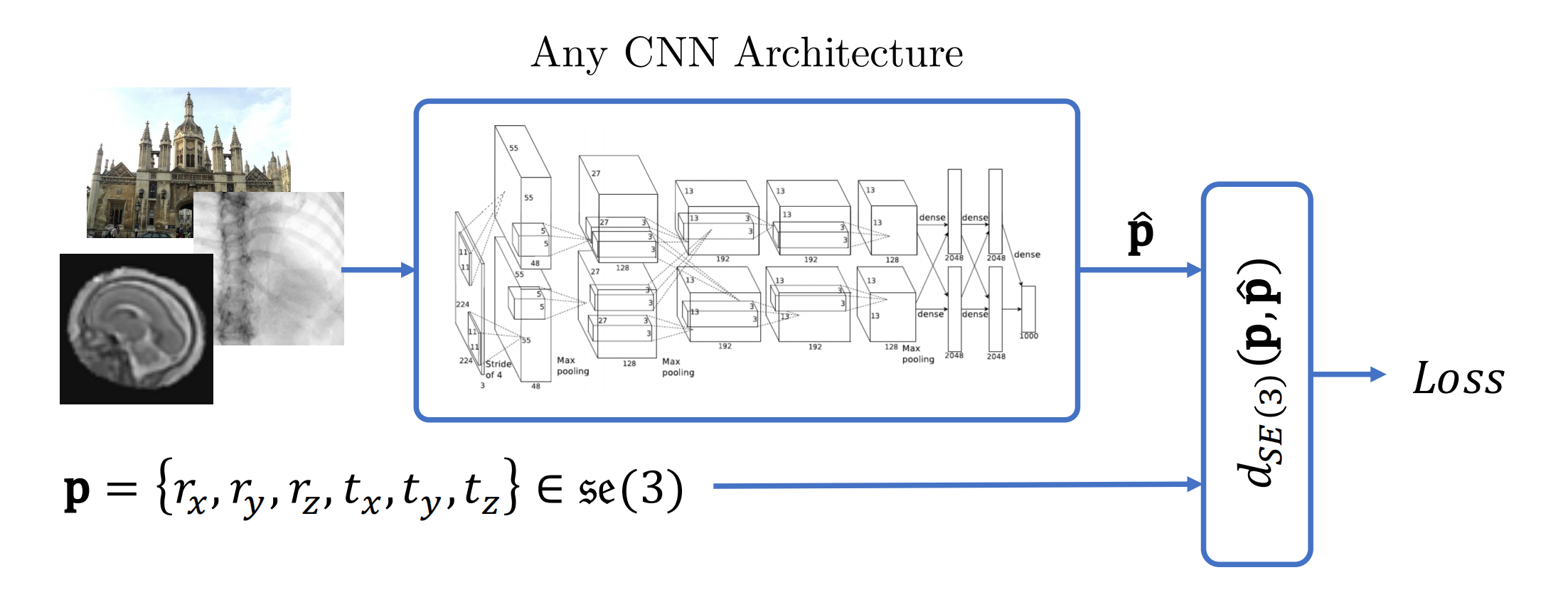
This code has been used for
- Benjamin Hou, Nina Miolane, Bishesh Khanal, Matthew Lee, Amir Alansary, Steven McDonagh, Joseph Hajnal, Ben Glocker, Daniel Rueckert, Bernhard Kainz, Computing CNN Loss and Gradients for Pose Estimation with Riemannian Geometry, 21st International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) 2018, 2018
- B. Hou, B. Khanal, A. Alansary, S. McDonagh, A. Davidson, M. Rutherford, J. V. Hajnal, D. Rueckert, B. Glocker, B. Kainz, 3-D Reconstruction in Canonical Co-Ordinate Space From Arbitrarily Oriented 2-D Images, IEEE Transactions on Medical Imaging, volume 37, pp.1737-1750, 2018
source code available on github.
Cortical Explorer
Ever wondered how the human brain works? Check out the Cortical Explorer by Sam Budd (Imperial MEng. final year student).
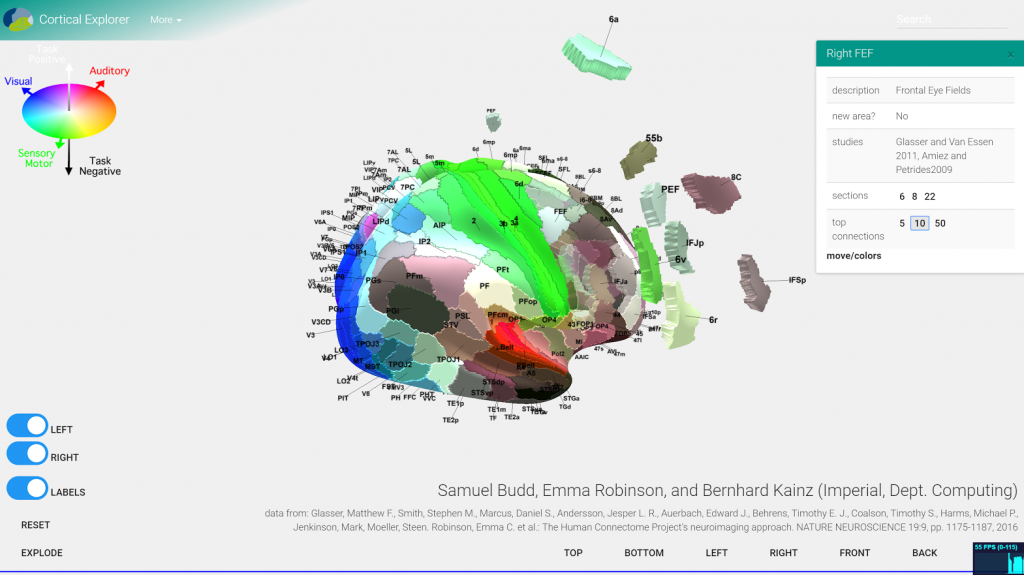
An early prototype Service-Oriented Architecture for cortical parcellation evlaution with multi-device, distributed front-end, i.e., a browser.
VR version (works with Oculus Rift in a browser): vr.corticalexplorer.com
SonoNet for real-time fetal standard scan plane detection
Identifying and interpreting fetal standard scan planes during 2D ultrasound mid-pregnancy examinations are highly complex tasks which require years of training. Apart from guiding the probe to the correct location, it can be equally difficult for a non-expert to identify relevant structures within the image. Automatic image processing can provide tools to help experienced as well as inexperienced operators with these tasks. In this paper, we propose a novel method based on convolutional neural networks which can automatically detect 13 fetal standard views in freehand 2D ultrasound data as well as provide a localisation of the fetal structures via a bounding box. An important contribution is that the network learns to localise the target anatomy using weak supervision only. The network architecture is designed to operate in real-time while providing optimal output for the localisation task. We present results for real-time annotation, retrospective frame retrieval from saved videos, and localisation on a very large and challenging dataset consisting of images and video recordings of full clinical anomaly screenings. The proposed method annotated video frames with an average F1-score of 0.86, and obtained a 90.09% accuracy for retrospective frame retrieval. Moreover, we achieved an accuracy of 77.8% on the localisation task.
Videos about this approach:
The SonoNet framework and models are available for download on github.
ShaderLab Framework
ShaderLab is a teaching tool to solidify the fundamentals of Computer Graphics. The ShaderLab framework is based on Qt5, CMake, OpenGL 4.0, and GLSL and allows the student to modify GLSL shaders in an IDE-like environment. The framework is able to render shaded polyhedral geometry (.off/.obj), supports image-based post-processing, and allows to implement simple ray-tracing algorithms. This tool will be intensively tested by 140 CO317 Computer Graphics students in Spring 2017.
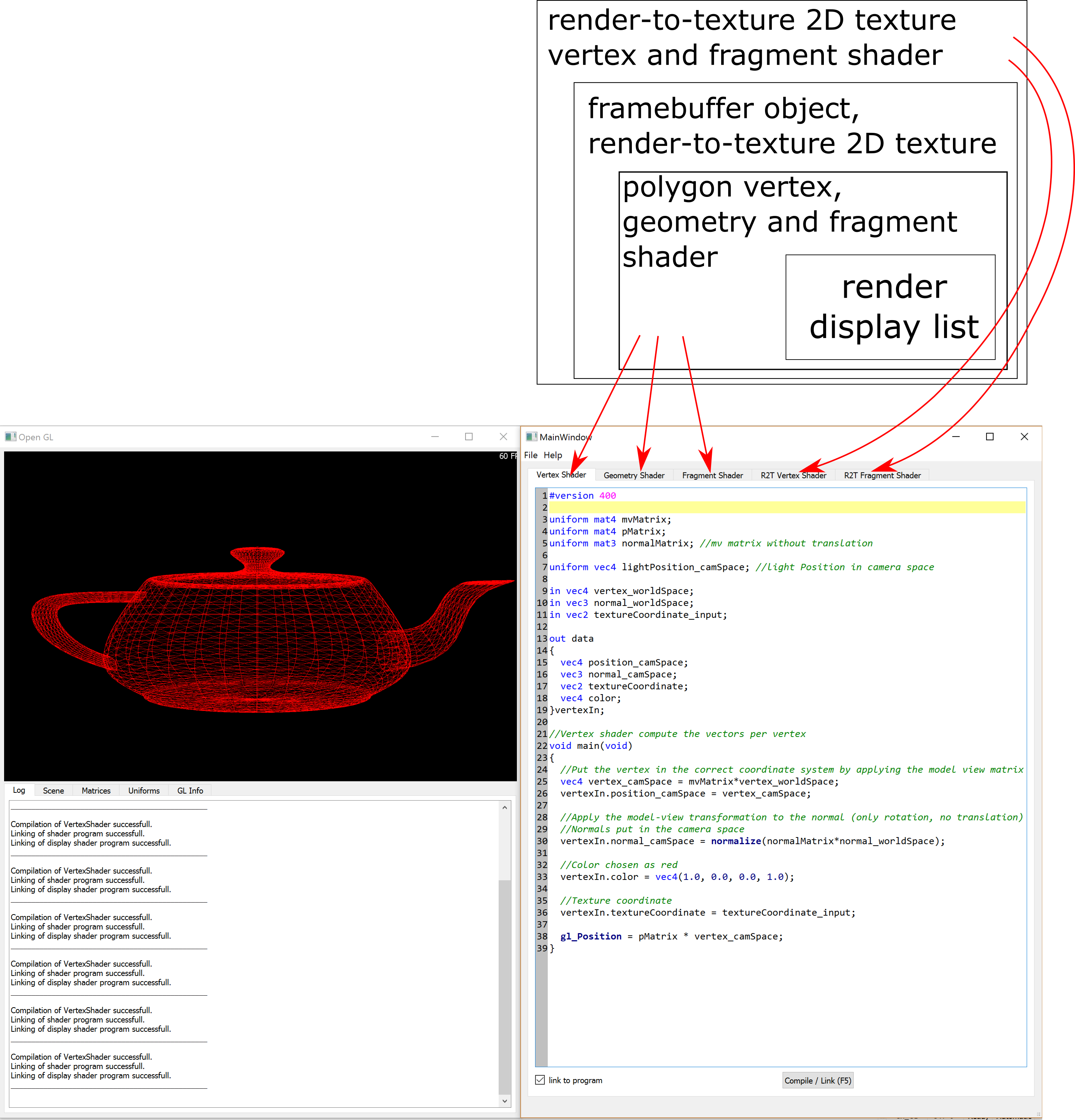
The ShaderLab framework is available for download on github.
PVR: Patch-to-Volume Reconstruction for Large Area Motion Correction of Fetal MRI
This tool implements a novel method for the correction of motion artifacts as acquired in fetal Magnetic Resonance Imaging (MRI) scans of the whole uterus. Contrary to current slice-to-volume registration (SVR) methods, requiring an inflexible enclosure of a single investigated organ, the proposed patch-to-volume reconstruction (PVR) approach is able to reconstruct a large field of view of non-rigidly deforming structures. It relaxes rigid motion assumptions by introducing a defined amount of redundant information that is addressed with parallelized patch-wise optimization and automatic outlier rejection. We further describe and provide an efficient parallel implementation of PVR allowing its execution within reasonable time on commercially available graphics processing units (GPU), enabling its use in the clinical practice. We evaluate PVR’s computational overhead compared to standard methods and observe improved reconstruction accuracy in presence of affine motion artifacts of approximately 30% compared to conventional SVR in synthetic experiments.
Furthermore, we have verified our method qualitatively and quantitatively on real fetal MRI data subject to maternal breathing and sudden fetal movements. We evaluate peak-signal-to-noise ratio (PSNR), structural similarity index (SSIM), and cross correlation (CC) with respect to the originally acquired data and provide a method for visual inspection of reconstruction uncertainty. With these experiments we demonstrate successful application of PVR motion compensation to the whole uterus, the human fetus, and the human placenta.
The source code for this approach is open source and publicly available for download on github.
GPU accelerated Motion compensation for medical images
Moving objects cause motion artefacts when their enclosing volume is acquired as a stack of image slices.
In this paper we present a fast multi-GPU accelerated implementation of slice-to-volume registration based super-resolution reconstruction with automatic outlier rejection and intensity bias correction. We introduce a novel fully automatic selection procedure for the image stack with the least motion, which will serve as an initial registration template. We fully evaluate our method and its high dimensional parameter space. Testing is done using artificially motion corrupted phantom datasets and using real world scenarios for the reconstruction of foetal organs from in-utero prenatal Magnetic Resonance Imaging and for the motion compensation of freehand compound Ultrasound data. On average we achieve a speed-up of more than 40x compared to a single CPU system, and another 1.70x for each additional GPU, while maintaining the same image quality as if calculated on a CPU. Our framework is qualitatively more accurate and on average 10x times faster than currently available state-of-the-art multi-core methods.
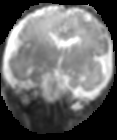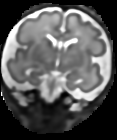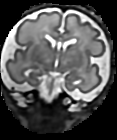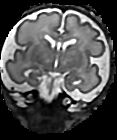
The source code for this approach is open source and publicly available for download on github.
SoftShell
Softshell, a novel execution model for devices composed of multiple processing cores operating in a single instruction, multiple data fashion, such as graphics processing units (GPUs). The Softshell model is intuitive and more flexible than the kernel-based adaption of the streamprocessingmodel, which is currently the dominant model for general purpose GPU computation. Using the Softshell model, algorithms with a relatively low local degree of parallelism can execute efficiently on massively parallel architectures. Softshell has the following distinct advantages: (1)work can be dynamically issued directly on the device, eliminating the need for synchronization with an external source, i.e., the CPU; (2) its three-tier dynamic scheduler supports arbitrary scheduling strategies, including dynamic priorities and real-time scheduling; and (3) the user can influence, pause, and cancel work already submitted for parallel execution. The Softshell processing model thus brings capabilities to GPU architectures that were previously only known from operating-system designs and reserved for CPU programming.
SoftShell 1.0.3 preview CUDA source (zip)
ScatterAlloc
ScatterAlloc is a dynamic memory allocator for the GPU. It is designed concerning the requirements of massively parallel execution. ScatterAlloc greatly reduces collisions and congestion by scattering memory requests based on hashing. It can deal with thousands of GPU-threads concurrently allocating memory and its execution time is almost independent of the thread count. ScatterAlloc is open source and easy to use in your CUDA projects.
ScatterAlloc 1.0.1 CUDA source (zip)
further development and bugfixes by ax3l et al. on github mallocMC
- Paper by Markus Steinberger, Michael Kenzel, Bernhard Kainz and Dieter Schmalstieg
- 2012, May 5th: Presentation at Innovative Parallel Computing 2012 by Bernhard Kainz
- Junior Thesis by Carlchristian Eckert (2014)
Volumetric Real-Time Particle-Based Representation of Large Unstructured Tetrahedral Polygon Meshes
Our version of GPUPBVR is a a particle-based volume rendering approach for unstructured, three-dimensional, tetrahedral polygon meshes. We stochastically generate millions of particles per second and project them on the screen in real-time. In contrast to previous rendering techniques of tetrahedral volume meshes, our method does not need a prior depth sorting of geometry. Instead, the rendered image is generated by choosing particles closest to the camera. Furthermore, we use spatial superimposing. Each pixel is constructed from multiple subpixels. This approach not only increases projection accuracy, but allows also a combination of subpixels into one superpixel that creates the well-known translucency effect of volume rendering. We show that our method is fast enough for the visualization of unstructured three-dimensional grids with hard real-time constraints and that it scales well for a high number of particles.