
Paul Kelly’s slides for a lunchtime talk at Imperial in June 2020 – aiming to provoke a little – how our algorithms textbooks are wrong/misguided, our architecture textbooks are wrong/misguided, our compilers textbooks are wrong/misguided. The key to this is the “Turing Tax” or “Turing Tariff” – leading to a manifesto for how we have to change how we think as the end of Moore’s Law looms.

This talk, delivered at Oxford and Edinburgh in late 2019, presents Firedrake, our domain-specific language project for solving partial differential equations using the finite element method – focusing on the compiler architecture issues that have been the focus of the SPO group’s involvement in the project.
Sajad Saeedi (ex-postdoc in SPO) giving an invited talk at CRV20 on our work on implementing convolutional neural networks using analogue SIMD computer inside the image sensor itself – using the University of Manchester’s amazing SCAMP5 device.

Automatic Code Generation for GPUs using Devito. This talk by my PhD graduate Fabio Luporini and my collaborator Gerard Gorman introduces Devito, a compiler for an embedded domain-specific language (embedded in Python) for solving partial differential equations using the finite difference method.
SLAMBench 3.0: Systematic Automated Reproducible Evaluation of SLAM Systems for Robot Vision Challenges and Scene Understanding. In this talk our collaborator Mihai Bujanca (University of Manchester) presents SLAMBench3 (paper, code), an open and systematic framework for comparing performance of different solutions for SLAM and real-time 3D scene understanding, with regard to performance, accuracy and power.
Real-Time 3D Scene Understanding: Volumetric SLAM using Octrees and Morton Number. Emanuele Vespa talking about his thesis work , the SuperEight library. The work was published as Emanuele Vespa, Nikolay Nikolov, Marius Grimm, Luigi Nardi, Paul H. J. Kelly, Stefan Leutenegger: Efficient Octree-Based Volumetric SLAM Supporting Signed-Distance and Occupancy Mapping.IEEE Robotics Autom. Lett. 3(2): 1144-1151 (2018)
Automatic Kernel Code Generation for Focal-plane Sensor-Processor Devices – Thomas Debrunner (now Head of Software at iniVation AG) presenting his MSc thesis project at the 2018 ARM Summit. The work was published as AUKE: Automatic Kernel Code Generation for an Analogue SIMD Focal-Plane Sensor-Processor Array. TACO 15(4): 59:1-59:26 (2019)
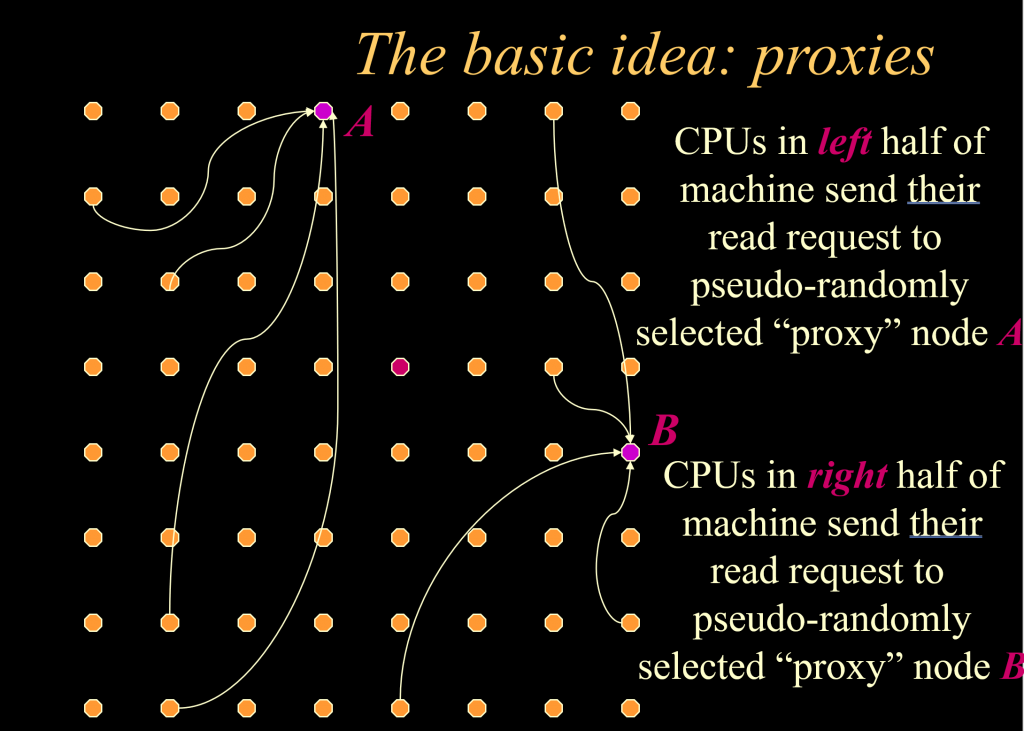
Adaptive Proxies: handling widely-shared data in shared-memory multiprocessors – Sarah A M Bennett (nee Talbot) and Paul H J Kelly, Euro-Par 2000. Cache-based shared memory systems are designed to do well on common workloads. What can we do to bound how bad things get on pathological workloads? This paper presents a modified cache coherency protocol that adds combining and randomisation to handle read contention (not so rare – think about pivot rows in Gaussian Elimination).
Compiling is like Skiing: this short video accompanies my lectures on Compilers for second-year students at Imperial College London. It introduces the main general theme of my research work: the design of software tools to generate programs, by automating optimisations that would be hard to write by hand. When we get this right, we can simultaneously raise the level of abstraction and simplicity for users, and also achieve higher performance than you might reasonably get by coding at a lower level.
The von Neumann Bottleneck and the Turing Tax: This is a lecture during the first week of my Advanced Computer Architecture (2020) course at Imperial, aiming to introduce a class discussion on the “Turing Tax” – the price to pay (in time, energy, transistor count etc) of running an application on a general-purpose computer instead of designing a special-purpose application-specific accelerator.
PyOP2: a Framework for Performance-Portable Unstructured Mesh-based Simulations. This presentation at SciPy 2013 by (then) PhD student Florian Rathgeber presents an outline of the architecture of the Firedrake compiler for the FEniCS project’s “UFL” DSL – which automates code generation for the finite element method. This talk focuses on PyOP2, the key abstraction for abstracting how we compute in parallel on an un structured mesh. PyOP2 is, in turn, a Python implementation of the OP2 abstraction developed by our collaborators Mike Giles, Gihan Mudalige and Istvan Reguly at Oxford.
Slides from older talks can be found here.